Quote
Yo hello everyone! Hope you’re all doing well. I’m still good and enjoying things.
Today, I want to share a bit about a situation I ran into when setting up a new node for my Kubernetes cluster. My node’s network wasn’t working, which caused delays for my application. Let’s dive in and see what was going on.
😄The Issue of Issue
Question
If you’ve already faced or are currently facing - Kubernetes DNS issues, you know they can create incredibly frustrating debugging moments that are far from easy. Consequently, I dedicated two days to learning and resolving the specific problem detailed below. This tutorial outlines precisely how I fixed it. Be sure to take note of this one!
In my experience, when attempting to self-host Kubernetes clusters, specifically on-premise solutions like K3s, RKE2, or other local Kubernetes setups, you’re likely to encounter a specific problem. Your pods might spin up, and components like CoreDNS, CNI, KubeProxy, and Kubelet appear to be functioning perfectly, yet your pods cannot communicate with services to resolve domains.
This issue then cascades, causing significant problems for health-checks, InitContainers, Jobs, Prehooking, and more, leaving you unsure where to even begin troubleshooting. Let’s list a couple of potential reasons, and I will separate into three levels, Rare, Unique and Special
-
(Rare) Your CoreDNS is in wrong configuration and CoreDNS can’t resolve your service domain with current configuration. These issues linked to
-
(Special) The Checksum TX is wrong configuration or not able fit with your kernel version in your network Interface, honestly to say if you encounter this problem, that ain’t gonna easy for understanding
-
(Unique) Firewall is turning on and there are some rules you settle up but make conflict with RKE2 or K3S, including
firewalld,ufworiptables. This one is not simple if you doesn’t understand what’s going on when turn on, turn off any rules in bunch of this 😄 -
(Special) Other situation relate with your kernel version, CNI, Network Policy, IP Exhaustion, Open Port, …
Info
Here are a couple of issues we might encounter when self-hosting. I know this list isn’t exhaustive, but we can always discuss more if either of us finds them later. Let’s go through each one to see what we have.
🔥 Firewall Related

Info
After spend bunch of hours to debug, I figure out my issue come from firewall which things I actually love and hate in Linux, especially Ubuntu because it’s really complicated
First of all, you can double-check my note about commands Iptables to figure rule and awesome things related about Linux firewall, and you can read them to update more about firewall knowledge
- Blog - iptables: a simple cheatsheet
- Gist - IP Tables (iptables) Cheat Sheet
- Medium - UFW: Uncomplicated Firewall — Cheat Sheet
- Digital Ocean - How To Set Up a Firewall Using FirewallD on CentOS 7
When I tried to list all my firewall rules, I discovered that UFW was actively running on my node and contained numerous rules that I suspected were causing packet loss (DROP)
While Ubuntu typically has open ports by default, enhanced security often involves integrating a firewall like firewalld, ufw, or iptables. The reason I checked iptables directly is that ufw or firewalld write their rules to iptables at a higher level, which can sometimes lead to overlooking critical conflicts. See these posts below to understand
- Blog - Making Rules For IPtables Firewall with UFW
- RockyLinux - iptables guide to firewalld - Introduction
This conflict arises because RKE2 and K3s inherently manage firewall rules for us. They export specific rules to control opening, closing, accepting, or dropping connections for their CNI (Container Network Interface), enabling pods and services to communicate. This pre-existing management by RKE2/K3s directly conflicts with other firewall configurations.
Let’s check and tackle with iptables first because you will have overview of whole firewall in system
# List all rules
sudo iptables -S | grep -e "ufw"Now you need to aware about this one, with default configuration of RKE2, you usually see it uses IP - 10.43.0.10 with Port UDP/53 for RKE2 CoreDNS with actually handle the tough job for resolving domain and let’s your service communicate each others
But some how, there are rules which set up for blocking your connection, you can simple test with command in node level but pre-define network or debug with Debug network with Pods inside your Kubernetes with dig command
dig @10.43.0.10 google.comf you can execute this command and receive a result within a few milliseconds, your CoreDNS is functioning correctly. However, if it fails or experiences delays, then your firewall could be a contributing factor to the problem. To address this, we’ll need to adjust some settings. The choice is yours, as disabling a firewall can be risky, but sometimes it’s a necessary step to understand the root cause. As per the K3s Documentation - UFW should be disabled.
For Ubuntu, that’s really simple
sudo ufw disableNow reboot your system and double-check again your RKE2, if your problem actual gone, congratulation 🎊 but not you can go for next part to see what we apply for CoreDNS and CNI
BTW, check your iptables and see anything else relating into UDP/53 for Kubernetes IP or Host IP
🌚 CoreDNS and Corefile
![]()
There aren’t going simple as well, especially relating into core of Kubernetes and CoreDNS is one of them. CoreDNS is a DNS Server which help you resolve internal domain of Kubernetes to IP, and you it broke your network inside Kubernetes will gonna die, seriously CoreDNS is blackbone for all stuff things related service and network inside Kubernetes.
We will not go deeper into CoreDNS, I will spend it for later articles but if you want to explore, you should double-check these contents
- CoreDNS Documentation
- Learning CoreDNS by @psycholog1st
- Blog - A Deep Dive into CoreDNS with Rancher: Best Practices and Troubleshooting
Go direct in RKE2 CoreDNS, RKE2 will install the coredns for first start as deployment with two replica, it means there are some reason why your CoreDNS will work perfect if CoreDNS land in node with not error with DNS issue. But in some situation, CoreDNS schedule to problem node, your cluster will encounter some problem when resolve domain, and it’s shitty disturb.
For enhancement, you can try to modify the Corefile which mount as Configmap in Kubernetes Cluster. To understand more, you should read them docs
- CoreDNS Documentation - Corefile Structure
- CoreDNS Blog - Corefile Explained
- Kubernetes Documentation - Customizing DNS Service
There are two points need to care in Corefile
log: Enable log to see or debug CoreDNS, by default it will Disableforward . /etc/resolv.conf: Any queries that are not within the Kubernetes cluster domain are forwarded to predefined resolvers (/etc/resolv.conf)
After I delve into these GitHub RKE2 - Containers can’t resolve hostnames and Blog - Pod DNS Problems to let me figure out to change DNS resolve to another like Google 8.8.8.8, I’m not sure because this action can drop your performance of your service but sometime you can give a try and find the fit way for your cluster. You can handle follow this step
# 1. Edit the configmap of your CoreDNS
kubectl edit cm -n kube-system rke2-coredns-rke2-coredns
# 2. Enhance the log and change default forward from
# /etc/resolv.conf --> 8.8.8.8
.:53 {
log # Enable log
errors
health {
lameduck 5s
}
ready
kubernetes cluster.local cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus 0.0.0.0:9153
forward . 8.8.8.8 # Instead for /etc/resolv.conf
cache 30
loop
reload
loadbalance
}
# 3. Restart your CoreDNS
kubectl rollout restart deployment -n kube-system rke2-coredns-rke2-corednsNow you can re-try and if it not resolve your problem, you can find out to unique situation which one I actually consider when apply it, but it’s fun and interesting. Let’s go to interface and CNI networking, tough choice
🌊 CNI - Network Interface and Checksum TX
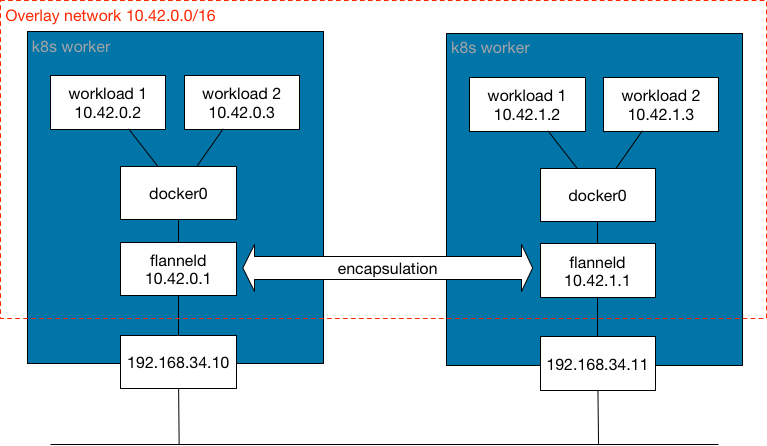
As you know, the CNI (Container Network Interface) serves as the network plugin for Kubernetes, defining numerous networking aspects, including network policy, pod-to-pod communication, and various features specific to each CNI, such as Cilium, Calico, Flannel, and Canal, among others.
By default, RKE2 versions 1.27.x and lower utilize the Flannel network plugin, while higher versions employ Calico. I won’t lie; you should generally keep your hands off these configurations, as any modification can be very dangerous and potentially bring down the entire system. That’s why I’m presenting this solution last—I believe you should thoroughly understand it before attempting to apply it. Even after using RKE2 for several months, Canal/Flannel still feel mysterious to me, as I rarely need to interact with them directly.
This particular issue is related to the kernel and ChecksumTX, a concept I knew little about until I encountered this specific situation. Its definition states: “The interface for offloading a transmit checksum to a device is explained in detail in comments near the top of include/linux/skbuff.h.” Essentially, it describes how to ensure your packet traverses the network interface correctly as part of the packaging process, including header offloading. (I hope I’m describing that accurately! 😢)

Following articles related to this problem, some suggested turning off the checksum on the Kubernetes network interface. However, you should definitely read this GitHub Issue - k3s on rhel 8 network/dns probleme and metrics not work. It details how they used tough techniques like sniffing, dumping, and dig on the network interface before concluding that the problem was indeed a bad checksum.
So they try to use ethtool - one of tool for modify interface in linux to fix this one, and off this checksum is one solution to deal with this type problem
sudo ethtool -K flannel.1 tx-checksum-ip-generic offAnd now they try again with dig command via IP Service of CoreDNS and it’s actually work, man that’s truly insane
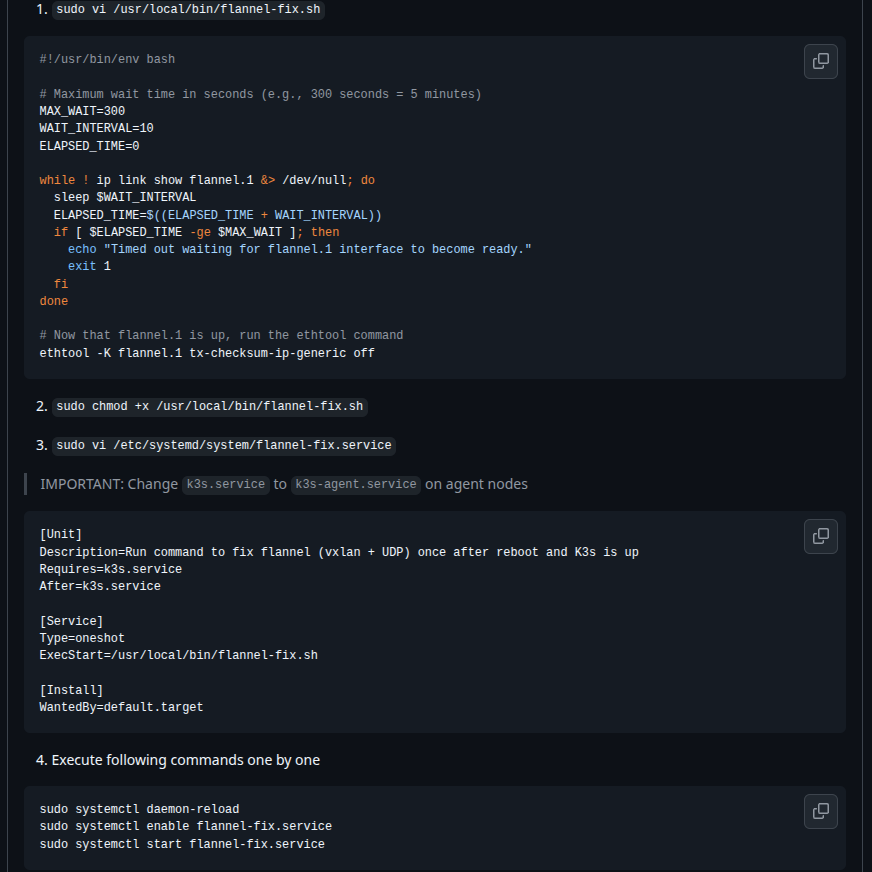
But I tell you before, it’s temporary solution when your service restart, your interface will turn on again with default configuration, so that why they write it to script and put that into systemd run after server or agent service worked at Link
Quote
This is truly an insane issue, one I never expected to encounter myself, and I bet it’d make many of you consider dropping or completely reinstalling your OS! 😄
🏋️♀️ Conclusion

Success
This is @all for this weekend, hope you enjoy your time with my articles and learn something via them. Out of 6 month, I see the Kubernetes world is really what insane and sometime rediculous but this push me more learning energy to figure out the new things, and that’s why we see this articles dropped
Quote
I’ll be working to balance my workload and continue learning and sharing more about technology. Therefore, I hope you all stay healthy, keep moving forward, and I’ll see you soon! Don’t forget to double-check Dueweekly Session 14