Quote
Hello y’ @all guy, nice to see you here. BTW, How is your week ? I’m feel pleasure for what I am learning and doing right now, currently I enjoy with my new job and explore new strategies for keeping learn about architecture and growth up in tech fields.
In this week, I will share about the technique that truly cool for optimizing your deployment became more efficiency. But in the system architecture nowadays, maybe you don’t know much about this one. Let’s say about Package Cache and Why you should use dependencies cache in your work.
Cache and The story of the power

Quote
If you are developer or who work in technologies field, you will hear about Cache at least one time. Cache helps you a lot of things, such as minimal your time to retrieve package frequently accessed from a couple of locations.
Actually I don’t have much experience when I use cache for my work as Developer, in some situations, I will meet that one or more time but It’s kinda importance for somehow, such as
- Cache in
Docker: If you work aroundDockerandDockefile, you will see your build progress which reuse couple of build store inside some location and help you skip this process but completely done. - If you use
node_modules, I think you can useinstallfor only one time before new module required you add into project - As Networking, sometime you will hear about
DNS Cache, that’s technique you will retrieve into couple ofDNS Serverto get caching before you load directly to host to get IP address
Quote
So let’s say, Cache is everywhere, anything process and you leverage this concept (architecture) to boost your application become more efficiency, fast and high experience quality.
Following, couple of articles, you can split Cache into two layer, one for Infrastructure and one for Technique & Strategies. If you can try to combine both of them, you will get the highest result ever seen, seriously
Infrastructure Cache (Cache Type)
Correct me if I am wrong, when I try to figure out Cache in Infrastructure layer, like article 9 Caching Strategies for System Design Interviews, There is three type caching corresponding, including
- Client Site Cache
- Server Site Cache
- Database Cache
That’s three types and It’s totally make sense, because most of techniques cache and structure that depend on three level in infrastructure layer to implement. You can find more information in couple of blogs
- EdgeMesh - Server-Side Caching vs. Client-Side Caching: The Differences (And Which Is Good For Your Website)
- AWS - Database Caching
When you try to take walkthough for each concept, you can reach to technique in programming for understand more how can they implement cache
Technique and Strategies Cache
When I try to read articles about cache, they list me some caches and it’s actually too much and sometime you just need to use 1 or 2 techniques but let’s see what kind suitable for your situation
- 9 Caching Strategies for System Design Interviews
- Advanced Caching Strategies in Node.js: Boosting Performance and Scalability
Let’s list a couple of candidates, such as
- In-Memory Cache
- Distributed Cache
- HTTP Caching
- Persistent Caching
- Write Through
- Write Back
- Cache-Aside
- …
Info
In terms of situations, you usually meet about
Distributed CachewithRedisorValkey,CDN, and in programming, I usually hear about Write through and Write Back. This look like very multiple and each type of them focus on solve couple of problems. FACT: In sometime, if you are using cache but not understand the strategies, cache will take damage back LOL 😄, e.g: data keeping not update, …
That’s why, you should know what you do and implement because it’s always exist pros and cons of any technologies.
Pros and Cons of Cache

When I try to research about Cache, I find some articles that interesting talk about Pros and Cons of Cache, like
- Pros and Cons of Caching Data in Software Development
- StackOverFlow - What are the Advantage and Disadvantage of Caching in Web Development
We can conclude about cache into typically dots, such as
Pros
- Cache increase speed to boost user experience
- Optimize resources used and improve performance
- Accelerate data retrieval
- …
Cons
- Risk of outdated content (stale data)
- Incorrect or corrupt cached data
- Security risk
- Overhead and Complexity
- …
One more thing, before we start into main topics of article, if you wanna understand more about Cache, what Cache in hardware actually work, you should check out at
Dependencies Cache
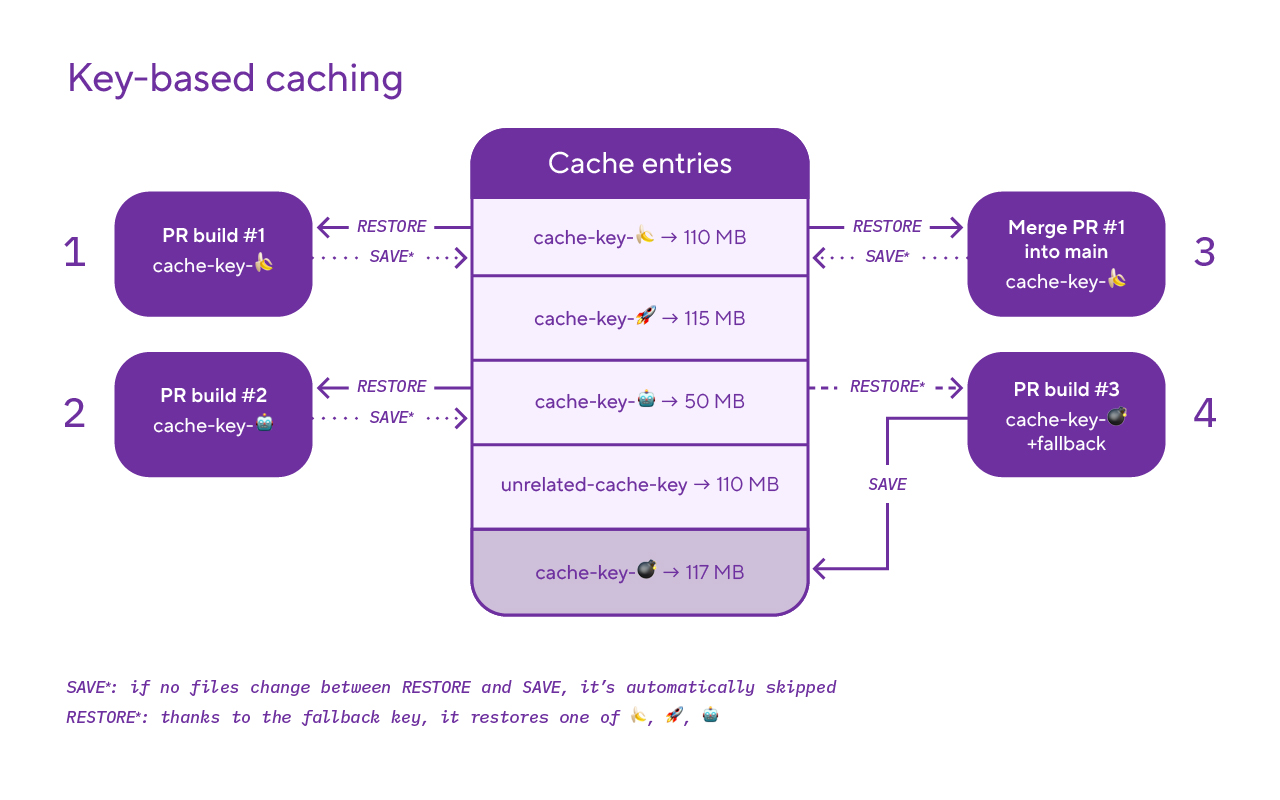
Source: Bitrise
Question
Ever you been ask yourself about how to optimize the build time in your CI/CD with applications for example AI or Big complex. You will trade off your time by building and encapsulating whole process into Docker Image, push that into registry and deploy to your server, that will take a lots time to completely process, so that why you need think about use cache for handle a bit about it for yourself.
Because like y’all guy, I truly surprise with these applied strategies, you can follow couple of stuff to imagine how we can deal with cache to boost your build.
- Python - Package index mirrors and caches
- Bitrise - CI/CD caching with Bitrise: Dependency caching with Bitrise
- Blog - DIY node_modules cache for Docker in your CI
- Gradle - Speed Up Maven Build
See that’s really cool stuff and you need to consider to prevent build from scratch for big application, if you can deal to build with cache, 100% your build and release progress will boost to new level, seriously
Let’s me describe a bit about node and python, there are two programming language you ever seen at least one time. With Python, you will have Pip or Poetry for packaging manager and with Node, you will have a lots, such as npm, yarn, or pnpm. Tons of them have one similar about using cache
You will see about how fast you install your package with pip or npm with not need to load again because it uses cache as key-value to retrieve your package from when it’s not exist in your project, it’s will read from there, load package for your project before hit to npm or pypi for finding your package. So you can leverage in this technique for boost up your build and release application, You can explore more at
Usually, if you not set any ENV or opt for these package manager, it will use cache for capture mostly validation package and put it package in to your home directory or ~/
Python
First we talk about Python and Pip
If you install package from Pypi via pip, you will use normal form like
pip install flaskThis command will install flask into your host and save flask cache into directory ~/.cache/pip for next using
But pip offer us to not take this action by adding another option
pip install --no-cache-dir flaskThis command will install flask into your host but not save cache and you will retrieve flask from Pypi for next installing
Info
You can’t see the big different right, yeah because if you download the huge package such as
pytorch,triton, this story will become make sense. It helps you call directly into cache and load package from cache to mem and install it for y’all
If you wanna know about pip cache directory, you can use command to find it
pip cache dirWarning
Recommended to NOT disable pip’s caching unless you have caching at a higher level (eg: layered caches in container builds). Doing so can significantly slow down pip (due to repeated operations and package builds) and result in significantly more network usage.
As you can see, pip is not recommending you disable whenever you know what you did it, but if you wanna it, you can try with ENV for disable it and it can help down size your built image into smaller than ever.
export PIP_NO_CACHE_DIR=offThis environment will disable cache for your host, if this environment exist, you will not gonna use cache for any more
Fell free to understand more reason why via discussion What is pip’s --no-cache-dir good for?
Node
How about node, is it the same as python ? The answer is yes and you can find your node cache via command
# Checks the integrity of your cache and ensures everything is in order
npm cache verify
# Find cache configuration
npm config get cacheThis strategies is kinda same as python, it will hit to cache and find with hash of package, retrieve from cache into memory and load into your project, if not found, it will hit to npm registry and download it.
You can explore more about at article Medium - NPM Caching: Speeding Up Your Development Process
If you use cache in CI/CD, you try to save the cache and reuse when you run command again
default:
image: node:latest
cache: # Cache modules in between jobs
key: $CI_COMMIT_REF_SLUG
paths:
- .npm/
before_script:
- npm ci --cache .npm --prefer-offline
test_async:
script:
- node ./specs/start.js ./specs/async.spec.jsstages:
- build
build:
stage: build
image: node:18.17.1
before_script:
- npm install --global corepack@latest
- corepack enable
- corepack prepare pnpm@latest-10 --activate
- pnpm config set store-dir .pnpm-store
script:
- pnpm install # install dependencies
cache:
key:
files:
- pnpm-lock.yaml
paths:
- .pnpm-storeYou can give a try and find more example via
Quote
By some techniques to compress that into file and save in local, you can reuse cache for optimizing your build time, retrieve the package from run time and do a lot of stuff for building with no struggle because of poor network.
Let’s see what use case, I try to apply for my work
Real cases and what I do for my job
When I meet the AI Application, The size image is really insane because some reason
- AI Engineer tries to package model inside image and makes it become more bigger
- AI Engineer installs package for AI and pack it into application, and make image become more bigger, let’s say 3 - 4 GB for
pytorch - In some ways, AI Engineer misses clean cache of
piporpoetryand try package that into package and you know what is it.
That’s reason why I should split the AI Code and model, package into two part, such as
- Build time: We just only rebuild the code when code actually change
- Run time: Setup environment by downloading package and models, loading and using it during runtime
Playground
So combination with Kubernetes, I suggest two option for building your MLflow by leveraging Kubernetes techniques
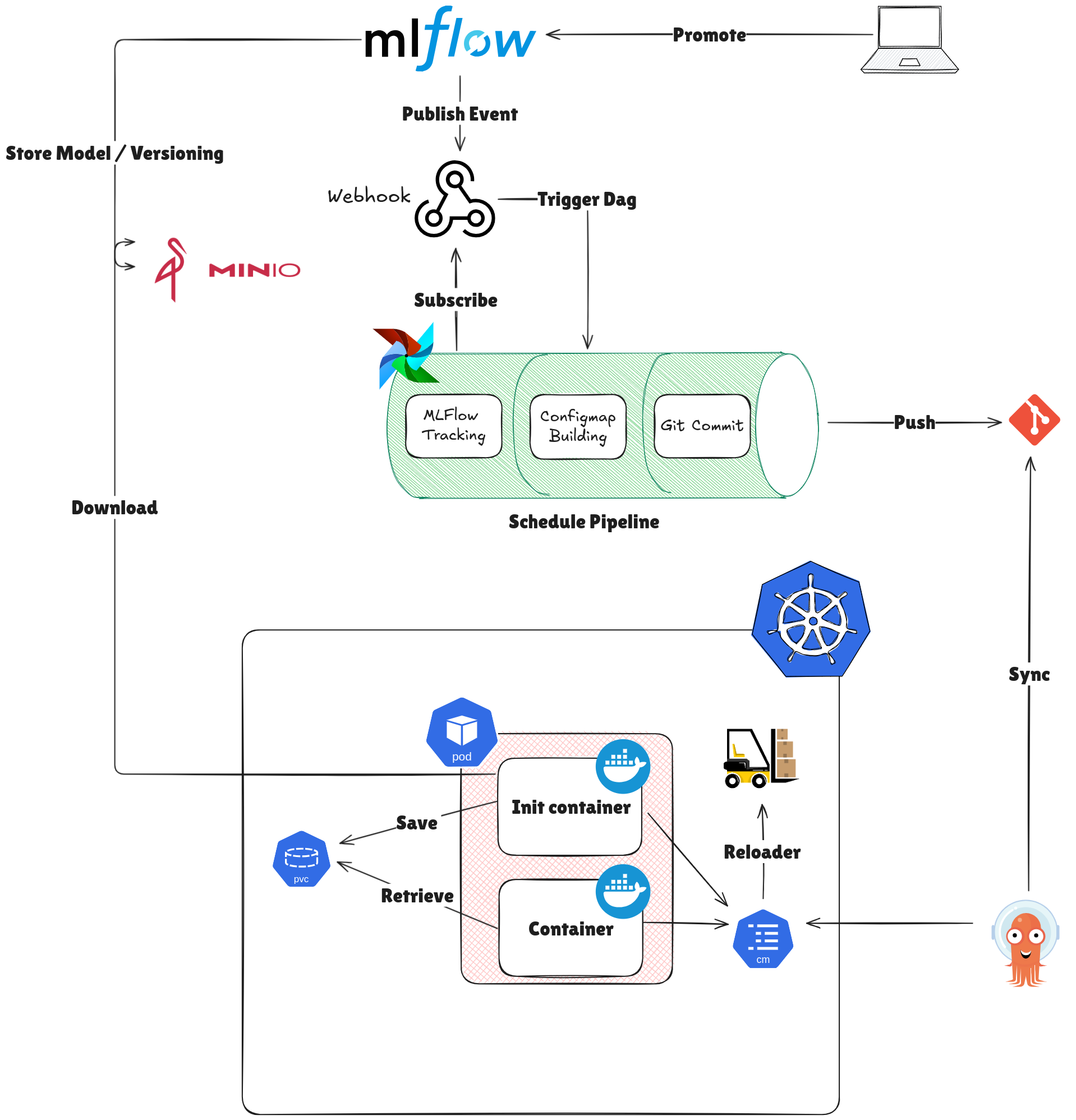
Use MLFlow with Airflow for Training and Inference Pipeline
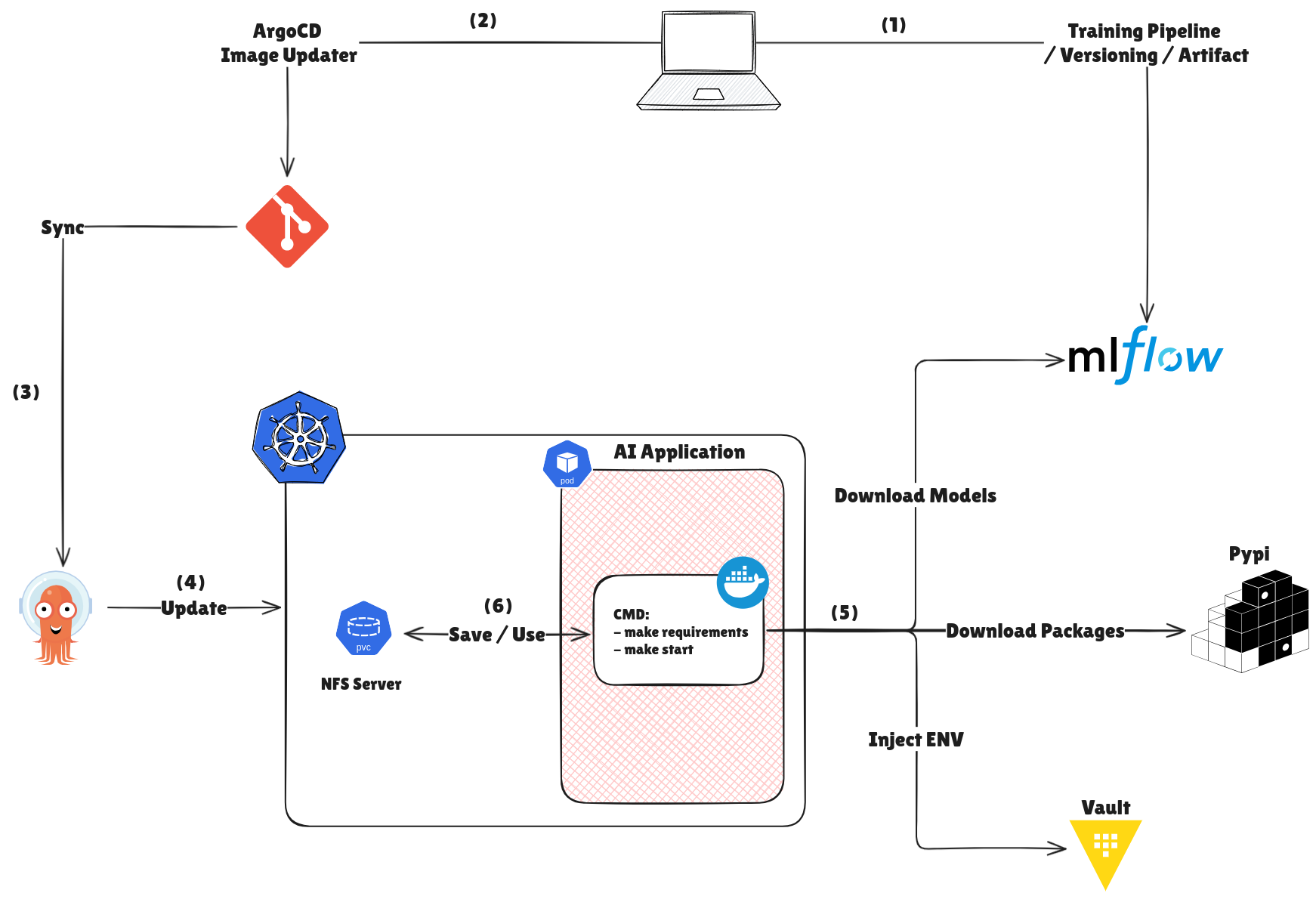
Use MLFlow for Inference Pipeline
So I design two options but with the purpose, let’s image
- In first step, AI Engineer will build model and log that into
MLflowfor keeping artifact.MLflowwill help you versioning and label your model for used.- If you work
airflow, you can use event promote inMLflowfor triggerDAGsworked and submit into webhook viapub/submodeling and building configmap for your application - If you are only use
Mlflow, you can use and playground withMLflowCLI to retrieve information of model
- If you work
- Build the docker image base on new code, push that into registry and wait for
argocd-image-updaterupdate the built image tag following GitOps flow with ArgoCD- With
Airflow, that will not need to build docker image, It just focus on building configure map and submit that into Git
- With
- ArgoCD will sync from Git into ArgoCD management and your configuration will transfer into Kubernetes
- Now update new configuration into your application, now you have option choose
syncor not to update your image. In terms of situation,auto-syncis enabling, you can go for it to update automatically into your AI Application - Trigger runtime to retrieve the package, models and secrets from multiple resources, It will help you reduce a lot of time by checking from cache (as PVC) before downloading from remote like
PypiorMLflow- The strategies will different when use
airflow, because it gracefully create new configmap and you config map to reload it, theconfigmapwill store who directory, path for configuration runtime - In terms of use only
mlflow, I will focus on setup via script file asrun-setup.shfor example to setup environment and help minimize step in Kubernetes command
- The strategies will different when use
- Package and models download from remote will be saved into PVC as Cache for next using, PVC will reuse
nfsstrategies, find more at Kubewekend Session Extra 1 to understand more about how to setupnfsas PVC
Following step by step, you can choose some one of tools for setup monorepo and centralize that into same way, such as
I decide to choose make and use makefile to control that one
requirements:
pip install -r requirements.txt
bash run-setup.sh
inference:
python3 inference.pyTo easier approaching, I will try to write run-setup.sh to support download, check and validate mode exist or not in PVC. But first of all, when you use MLflow as model registry, you should setup some environment variable, like
LOCAL_MODEL_PATH: Use for specific location for storing downloading model (e.g:/src/models)MLFLOW_MODEL_NAME: Use for specific model name when you log in MLflow (e.g:set_fit_model)MLFLOW_MODEL_VERSION: Use for specific version of model inside registryMLFLOW_TRACKING_USERNAME: Username for access into MLflowMLFLOW_TRACKING_PASSWORD: Password for access into MLflowMLFLOW_TRACKING_URI: Tracking URI of MLflow
#!/bin/bash
# # MLflow # #
MLFLOW_MODEL_NAME="$MLFLOW_MODEL_NAME" MLFLOW_MODEL_VERSION="$MLFLOW_MODEL_VERSION"
# # GENERAL # #
LOCAL_MODEL_PATH="$LOCAL_MODEL_PATH"
if [ -d "$LOCAL_MODEL_PATH/$MODEL_REGISTRY/$MLFLOW_MODEL_VERSION" ]; then
echo "Model already exists at $LOCAL_MODEL_PATH/$MODEL_REGISTRY/$MLFLOW_MODEL_VERSION. Skipping download."
else
echo "Model not found. Downloading..."
mkdir -p "$LOCAL_MODEL_PATH" # Create if it doesn't exist
# # Download the model
mlflow artifacts download --artifact-uri "models:/$MLFLOW_MODEL_NAME/$MLFLOW_MODEL_VERSION" \
--dst-path "$MODELS_DIR/$MODEL_REGISTRY/$MLFLOW_MODEL_VERSION" || rm -rf $MODELS_DIR/$MODEL_REGISTRY/$MLFLOW_MODEL_VERSION
# Verify download (essential!)
if [ -d "$LOCAL_MODEL_PATH/$MODEL_REGISTRY/$MLFLOW_MODEL_VERSION" ]; then
echo "Model downloaded successfully to $LOCAL_MODEL_PATH/$MODEL_REGISTRY/$MLFLOW_MODEL_VERSION"
else
echo "ERROR: Model download failed"
exit 1
Now package that into Dockerfile and push into registry
At the end of application, you can try to setup PVC and Command into your application manifest, and your cache will work, first time will slow but second time will faster
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: ai-deployment
spec:
replicas: 1
selector:
matchLabels:
app: ai-deployment
template:
metadata:
labels:
app: ai-deployment
spec:
containers:
- command:
- "/bin/sh"
- "-c"
- "make requirements && make inference"
image: python:3.10-buster
name: ai-deployment
volumeMounts:
- name: models-package-cache
mountPath: /src/models
subPath: ./data/models/
- name: models-package-cache
mountPath: /root/.cache/pip
subPath: ./data/cache/pip
- name: models-package-cache
mountPath: /root/.cache/pypoetry
subPath: ./data/cache/poetry
volumes:
- name: models-package-cache
persistentVolumeClaim:
claimName: cache-pvcNow run apply and you will see result
kubectl apply -f deployment.yamlTroubleshoot and Optimize
With the implementation, in term of situations, we will encounter a couple of problems and we need to figure out the solution for tackling with them, including
1. Is the implementation suitable for replica > 2 ?
Yes, in the good ways, we can configure to help multiple pods that rolling update sequentially.
Use strategies RollingUpdate deployments, explore more in there Deployments, It means when we set .spec.strategy.type==RollingUpdate. You can specify maxUnavailable and maxSurge to control the rolling update process.
With default configuration, maxUnavailable and maxSurge will set for 25%, It means at least one pod can be create new and one pod can be available in replicasets
In the run-setup.sh script, it’s will have check and ignore when the model is truly existence
if [ -d "$LOCAL_MODEL_PATH/$MODEL_REGISTRY/$MLFLOW_MODEL_VERSION" ]; then
echo "Model already exists at $LOCAL_MODEL_PATH/$MODEL_REGISTRY/$MLFLOW_MODEL_VERSION. Skipping download."2. Throttling CPU when load package from cache to pods
When Pod use pip or poetry to download package from PyPi or cache, we will encounter a couple of problems about CPU Utilization, for example
- The download and load progress is executed, that will find the resource inside
Cachebefore hit toPyPi. In term of situations, Cache exist package requirements, that will load from Cache into Memory and reserve CPU for load Cache into application. - With CPU on cloud, sometime It will have less core and frequency MHz, so In bad way It will make the download slow a bit but willing completely as well
When we explore about the issue at Pip build option to use multicore , we can intercept about in default, Pip will use only one core for downloading and that can cause Throttling CPU
But we can try to setup add-on --install-option="--jobs=6" for pip or use that one with make via MAKEFLAGS="-j$(nproc)"
Use with Pip
pip3 install --install-option="--jobs=6" PyXXXUse with Make
export MAKEFLAGS="-j$(nproc)" make requirementsConclusion

Success
It’s too long for write a bit again, because I hold this blog too long and maybe release couple week ago but now we have it, no reason why LOL. Hope you get well and find information for your work, it’s such wonderful adventure when I try to learn about cache and build up some strategies can be applied into AI Application, that will great as well
Quote
One week pass through, I just sit and write back again after long time and focus on other work, maybe I just let my self enjoy more with tech than force into discipline same last year. I truly enjoy, learn and figure out what should I do for next path, so you can do too, just keep run, learn, have fun and stay safe. See you in next week and now see yah