Quote
Hi @all, I’am back after the week to take the break, but unlucky I have sick and don’t have much time to think about the ideal to work with DevOps, Kubewekend or Cloud Services. Therefore, I will learn with you about Milvus - Vector Database, and it’s going to grow up rapidly to become potential things for community AI and ML, totally opensource. Let’s digest
What is Vector Database?
First of all, usually I will try to learn from core of things what we try to research, and Milvus is one of vector database. So, what is vector database? Some articles was talked about this topics with good ideas, such as
- Cloudflare - What is a vector database?
- AWS - What is a Vector Database?
- Nam Nguyễn - Vector Database – Vai trò quan trọng trong chiến lược AI
Info
Vector Database
A collection of data stored as mathematical representations. Vector databases make it easier for machine learning models to remember previous inputs, allowing machine learning to be used to power search, recommendations, and text generation use-cases. Data can be identified based on similarity metrics instead of exact matches, making it possible for a computer model to understand data contextually.
(Cloudflare - What is a vector database?)
Vector Database make it possibles for computer program can easily to compare, identify relationship and understand context. This technique is creation advanced of LLM (Large Language Models) nowadays
Info
Each vector in a vector database corresponds to an object or item, whether that is any typical data such as image, video, document, … These vectors are likely to be lengthy and complex, expressing the location of each object along dozens or even hundreds of dimensions.
Vector Database take lots of advantage in
- Store the data in multi dimensions
- Similarity and semantic searches
- Machine learning and deep learning
- Large language models (LLMs) and generative AI
- Analysis the big data
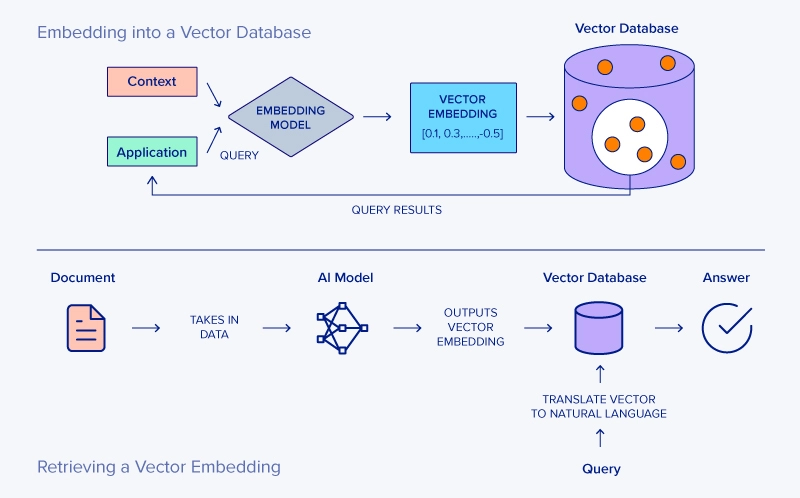
To make conversation with Vector Database, there is one technique creation called Embeddings - Vectors generated by neural networks. It means this one is typical vector database for a deep learning model is composed of embeddings, when neural network work to fine-tuned, It will generate embeddings and not need to create that manually.
Info
With Vector Database, It brings back a good quality, enhance the power with better cost.
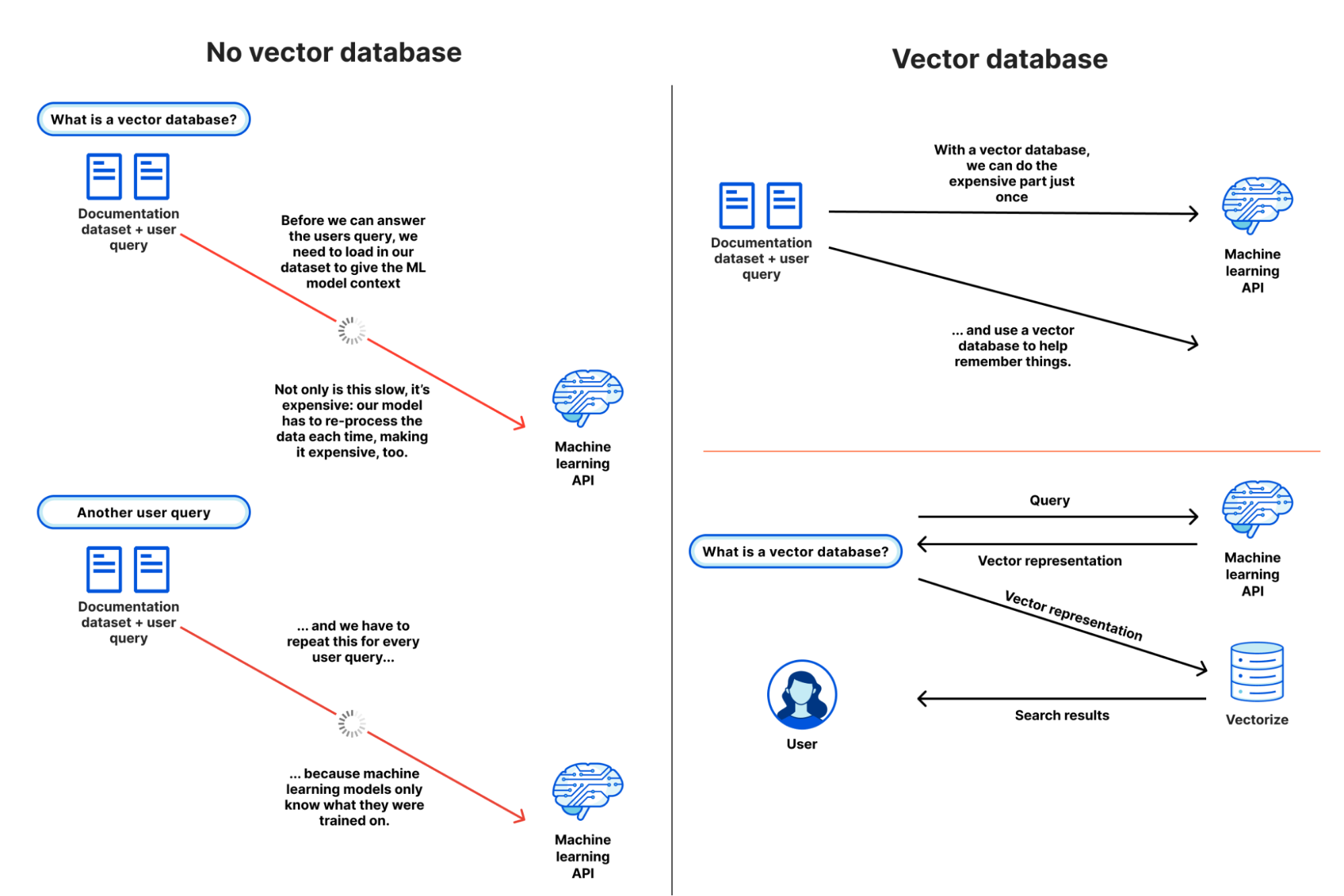
When you work with querying machine learning, you will need to pass whole context to model, and really slow with huge data to processing, It means you cost a lot of money to computing, and this work will repeat again and again.
There is reason why Vector Database handy, with vector database you will have pass your dataset once time, and the model’s embeddings of that data are stored in a vector database.
For time to queries, you will save a lot because you just need parse embeddings, and wait for return your result. You will not need to handy with preprocess data before pass to model, that why you will don’t wait to long to take your result turn back with same context you passing, another computing process and analysis through embeddings vector mapping with vector database.
Nowadays, you have more potential to get familiar with vector database, some candidate can be listed, such as
- Milvus : The High-Performance Vector Database Built for Scale (Opensource)
- faiss: A library for efficient similarity search and clustering of dense vectors. (Opensource)
- Qdrant: An AI-native vector dabatase and a semantic search engine (Opensource)
- Chroma: The AI-native open-source vector database (Opensource)
- Weaviate: An open source, AI-native vector database (Opensource)
Quote
So I think, we reach to important part, best candidate or target of article. Milvus
Milvus Database
![]() To find more information about technology, setup, API SDK and more things about Milvus, feel free access at Milvus Docs
To find more information about technology, setup, API SDK and more things about Milvus, feel free access at Milvus Docs
Introduce
Info
Milvus
A high-performance, highly scalable vector database that runs efficiently across a wide range of environments, from a laptop to large-scale distributed systems. It is available as both open-source software and a cloud service.
Milvus is an open source under LF AI & Data Foundation and receive the huge code contributor from multiple companies and communities, such as Zilliz, ARM, NVIDIA, AMD, Intel, …
As I relate in part vector database, Milvus is using to carrying unstructured data (image, audio, text, …) into structured collections. It supports a wide range of data types for different attribute modeling, including common numerical and character types, various vector types, arrays, sets, and JSON, saving you from the effort of maintaining multiple database systems.
Milvus will provide us three typical deployment mode, depend on your situation to pick one of them to bring back efficiency
- Milvus Lite: A Python library that can be easily integrated into your applications. You can use that for POC in Jupyter notebooks or running on edge devices with limited resources.
- Milvus Standalone: A single-machine server deployment, with all components bundled into a single Docker image for convenient deployment.
- Milvus Distributed: A operator and deployment into Kubernetes Cluster, featuring a cloud-native architecture designed for billion-scale or even larger scenarios. This architecture ensures redundancy in critical components.
Architecture and Design
Info
One of most impressed of Milvus make that become different between vector database out there, because stand behind that include multiple techniques, storage object and algorithms when developers try to integrate, and change Milvus performance become insane
You can read about What Makes Milvus so Fast ? This high performance is the result of several key design decisions:
- Hardware-aware Optimization - Optimizes to use over many hardware architectures
- Advanced Search Algorithms - Uses in-memory and on-disk index/search algorithm
- Search Engine in C++ - Uses C++ for this critical component
- Column-Oriented - A column-oriented vector database system
The powerful of Milvus is Scalable, that have these components from Storage Object, Message Storage, … to able perform rapidly scaling, and provide ability to expand current cluster with power of Cloud Native, and the result is insane 🥶
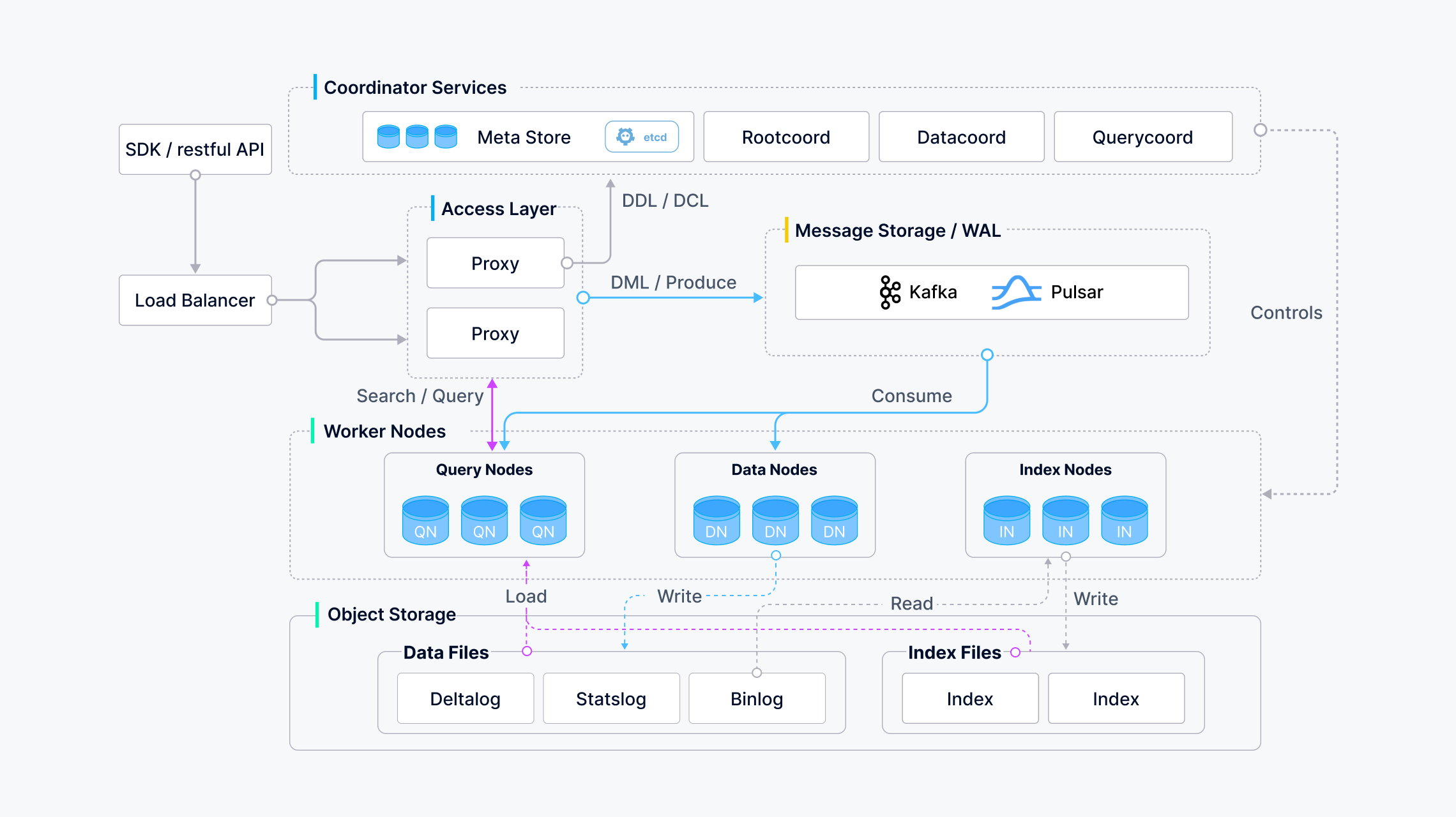
Milvus Archiecture Diagram (Source: Milvus Doc)
Now we take a look Milvus Architecture, the whole one with the image above. To utilize and exploit Milvus, Milvus recommended about operating this platform inside Kubernetes for optimal availability and elasticity.
These algorithms are used by Milvus focus search libraries including Faiss, HNSW, DiskANN, SCANN and more
Milvus supports data sharding, streaming data ingestion, dynamic schema, search combine vector and scalar data, multi-vetor and hybrid search, sparse vector and many other advanced functions. Learn more at Types of Searches Supported by Milvus
Milvus adopts a shared-storage architecture featuring storage and computing disaggregation and horizontal scalability for its computing nodes. Following the principle of data plane and control plane disaggregation, Milvus comprises four layers: access layer, coordinator service, worker node, and storage. These layers are mutually independent when it comes to scaling or disaster recovery.
You can run Milvus with two modes: Standalone and Cluster. They will have same feature but different about choosing for dataset size, traffic data, and more.
Learn about four layers
First of all, we will check about access layer
Composed of a group of stateless proxies, the access layer is the front layer of the system and endpoint to users
- Proxy is in itself stateless
- As Milvus employs a massively parallel processing (MPP) architecture
Next, Coordinator service

This one is core service as Milvus system’s brain. The tasks it takes on include cluster topology management, load balancing, timestamp generation, data declaration, and data management. There are three coordinator types
- Root Coord - Handles data definition language (DDL) and data control language (DCL) requests, such as create or delete collections, partitions, or indexes, as well as manage TSO and time ticker issuing
- Query Coord - Manages topology and load balancing for the query nodes, and handoff from growing segments to sealed segments.
- Data Coord - Manages topology of the data nodes and index nodes, maintains metadata, and triggers flush, compact, and index building and other background data operations.
Then, Worker Node

Worker nodes are dumb executors that follow instructions from the coordinator service and execute data manipulation language (DML) commands from the proxy. And It work as stateless components, therefore easily to scaling when need to expand or disaster recovery. There are three types of nodes
- Query node - Retrieves incremental log data and turn them into growing segments by subscribing to the log broker, loads historical data from the object storage, and runs hybrid search between vector and scalar data.
- Data node - Retrieves incremental log data by subscribing to the log broker, processes mutation requests, and packs log data into log snapshots and stores them in the object storage.
- Index node - Builds indexes, and Index nodes do not need to be memory resident, It can be implemented with the serverless framework.
Last, Storage



Storage is the bone of the system, responsible for data persistence. It comprises meta storage, log broker, and object storage.
-
With Meta Store, It uses etcd - key value store to help keep snapshots of metadata such as collection schema, and message consumption checkpoints. With
etcd, Meta Store will receive the best feature supportive to extremely high availability, strong consistency, and transaction support, parallel handle service registration and health check. -
About Object Storage, It will stores snapshot files of logs, index files for scalar and vector data, and intermediate query results. Milvus will use MinIO as object storage with combination for Azure Blob and AWS S3, with support of two platforms bring more cost-efficiency but latency when access, therefore Milvus want to bring the plan to storage to cold-hot data separation with power of hardware, on-memory or in-disk SSD
-
The important, the backbone of Milvus, Log Broker is a pub-sub system that supports playback, responsible for streaming data persistence and event notification, ensures integrity of the incremental data when the worker nodes recover from system breakdown. Milvus cluster uses Pulsar or Kafka, and with Milvus standalone uses RocksDB
-
Milvus built around log broker following the “log as data” principle, guarantees data reliability through logging persistence and snapshot logs. Because Milvus use pub-sub architecture, so that will separate two role: log broker (maintain log sequence) and log subscriber.
Note
The former records all operations that change collection states; the latter subscribes to the log sequence to update the local data and provides services in the form of read-only copies. The pub-sub mechanism also makes room for system extendability in terms of change data capture (CDC) and globally-distributed deployment.
Data Process
Info
In this part, we will try to research about the way Milvus perform data insertion, index building, and data query. But It’s really tough, and bit confused
Data insertion
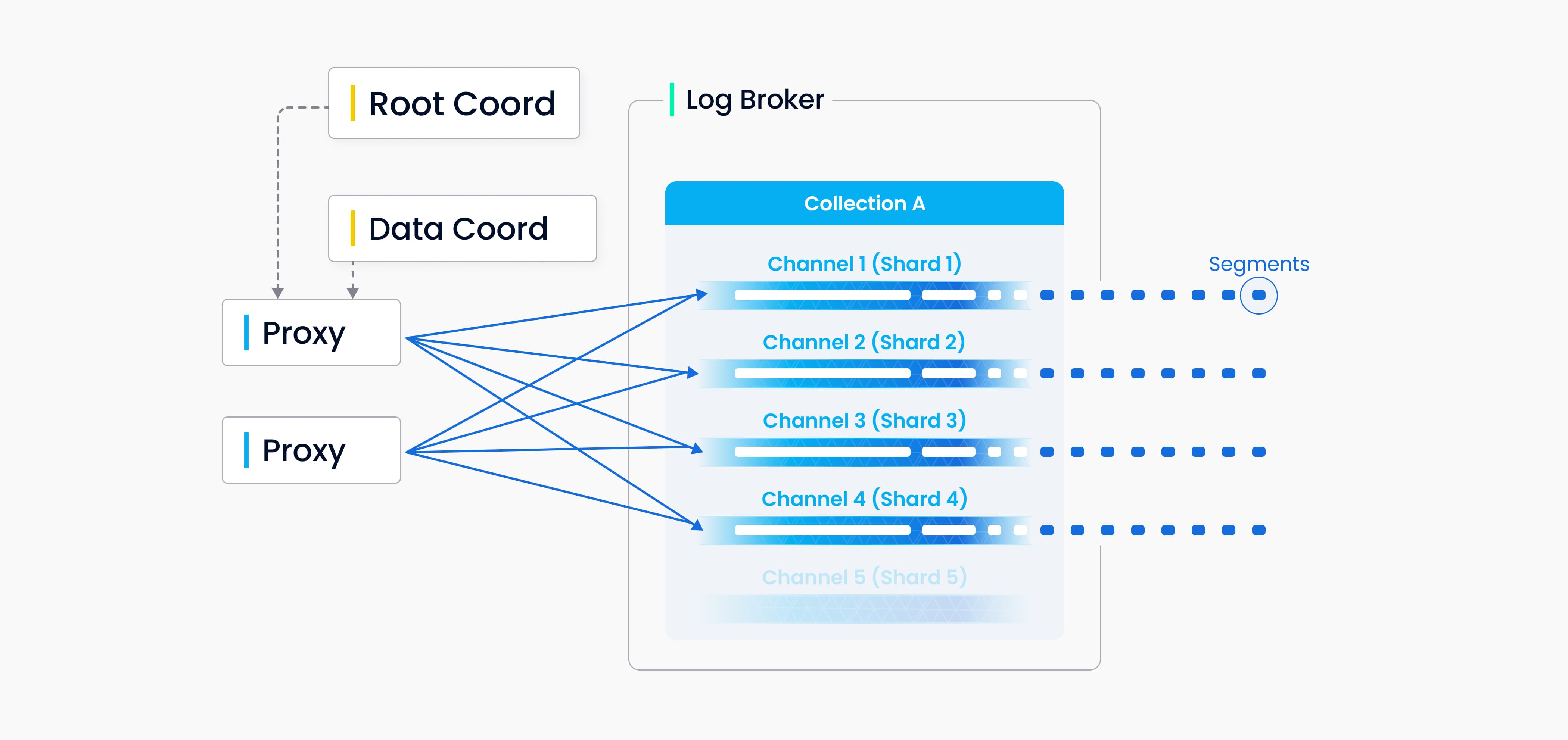
Data Insert 1 (Source: Milvus Doc)
We can specify number shard for each collection and corresponding to a virtual channel (vchannel), Milvus will assign vchannel in the log broker a physical channel (pchannel). Any Any incoming insert/delete request is routed to shards based on the hash value of primary key.
Validation of DML requests is moved forward to proxy and assign time stamp for each insert/delete request from TSO with colocates with Root Coord. With the older timestamp being overwritten by the newer one, timestamps are used to determine the sequence of data requests being processed. Proxy retrieves information in batches from Data Coord including entities’s segments and primary keys to increase overall throughput and avoid overburdening the central node
Info
Both DML (data manipulation language) operations and DDL (data definition language) operations are written to the log sequence, but DDL operations are only assigned one channel because of their low frequency of occurrence.
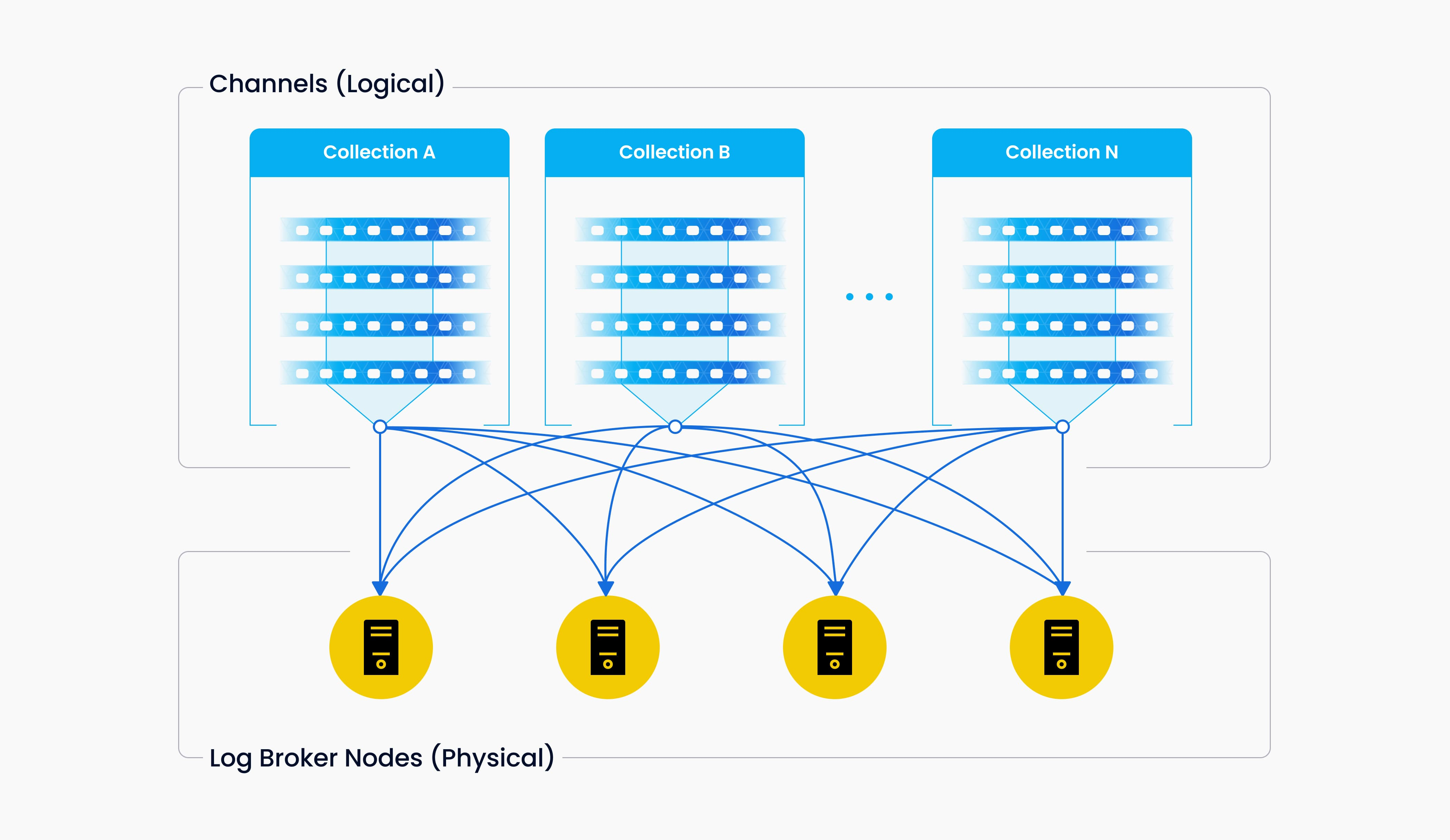
Data Insert 2 (Source: Milvus Doc)
Info
Vchannels are maintained in the underlying log broker nodes. Each channel is physically indivisible and available for any but only one node
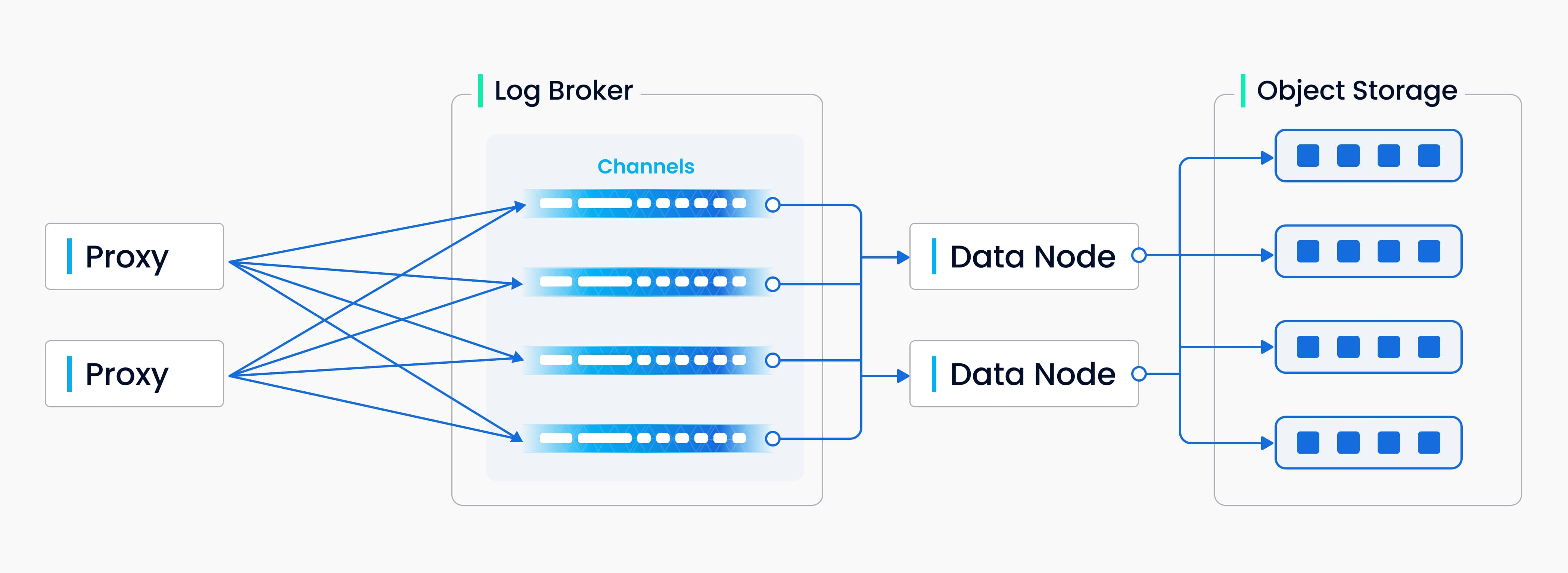
Write data to sequence (Source: Milvus Doc)
The process involves four tasks: validation of DML requests, publication-subscription of log sequence, conversion from streaming log to log snapshots, and persistence of log snapshots. The four tasks are decoupled from each other to make sure each task is handled by its corresponding node type. Nodes of the same type are made equal and can be scaled elastically and independently to accommodate various data loads, massive and highly fluctuating streaming data in particular.
Index building
Info
Index building is performed by index node. To avoid frequent index building for data updates, a collection in Milvus is divided further into segments, each with its own index.
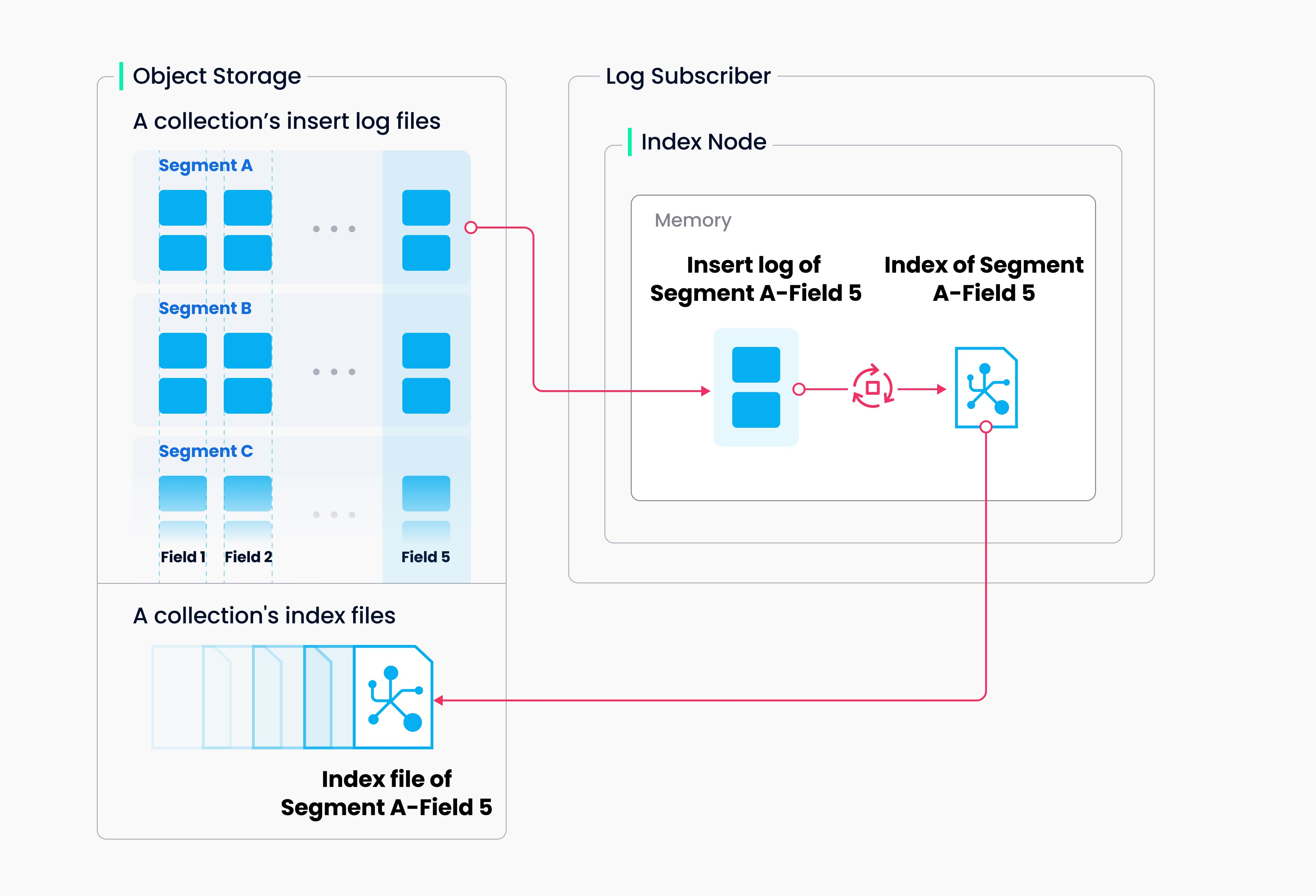
Index building (Source: Milvus Doc)
Milvus supports building index for each vector field, scalar field and primary field. Both the input and output of index building engage with object storage: The index node loads the log snapshots to index from a segment to memory, deserializes the corresponding data and metadata to build index, serializes the index when index building completes, and writes it back to object storage.
Data query
Info
Data query refers to the process of searching a specified collection for k number of vectors nearest to a target vector or for all vectors within a specified distance range to the vector. Vectors are returned together with their corresponding primary key and fields.
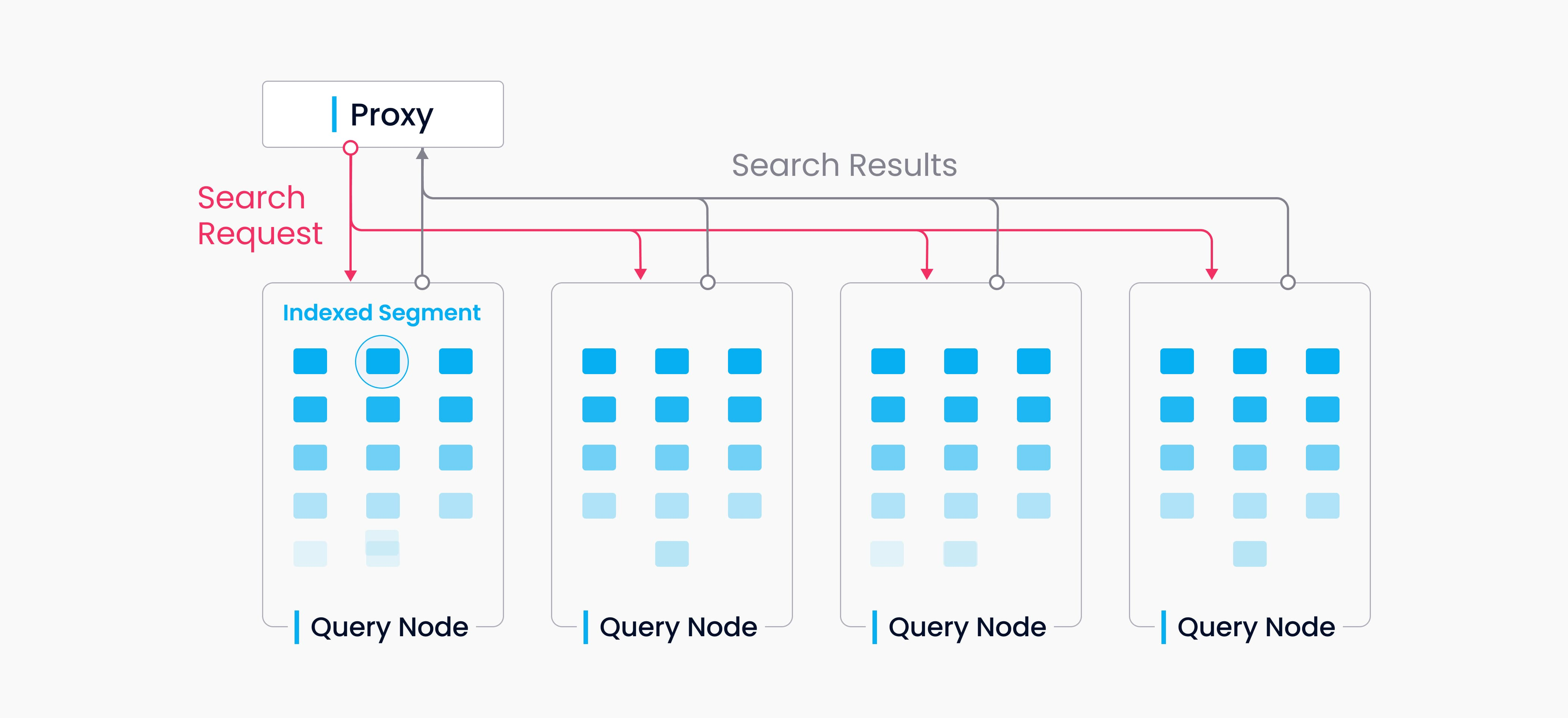
Data Query (Source: Milvus Doc)
A collection in Milvus is split into multiple segments, and the query nodes loads indexes by segment. When a search request arrives, it is broadcast to all query nodes for a concurrent search. Each node then prunes the local segments, searches for vectors meeting the criteria, and reduces and returns the search results.
Query nodes are independent from each other in a data query. Each node is responsible only for two tasks: Load or release segments following the instructions from query coord; conduct a search within the local segments. And Proxy will reduce search result from each node and returning the final result to client
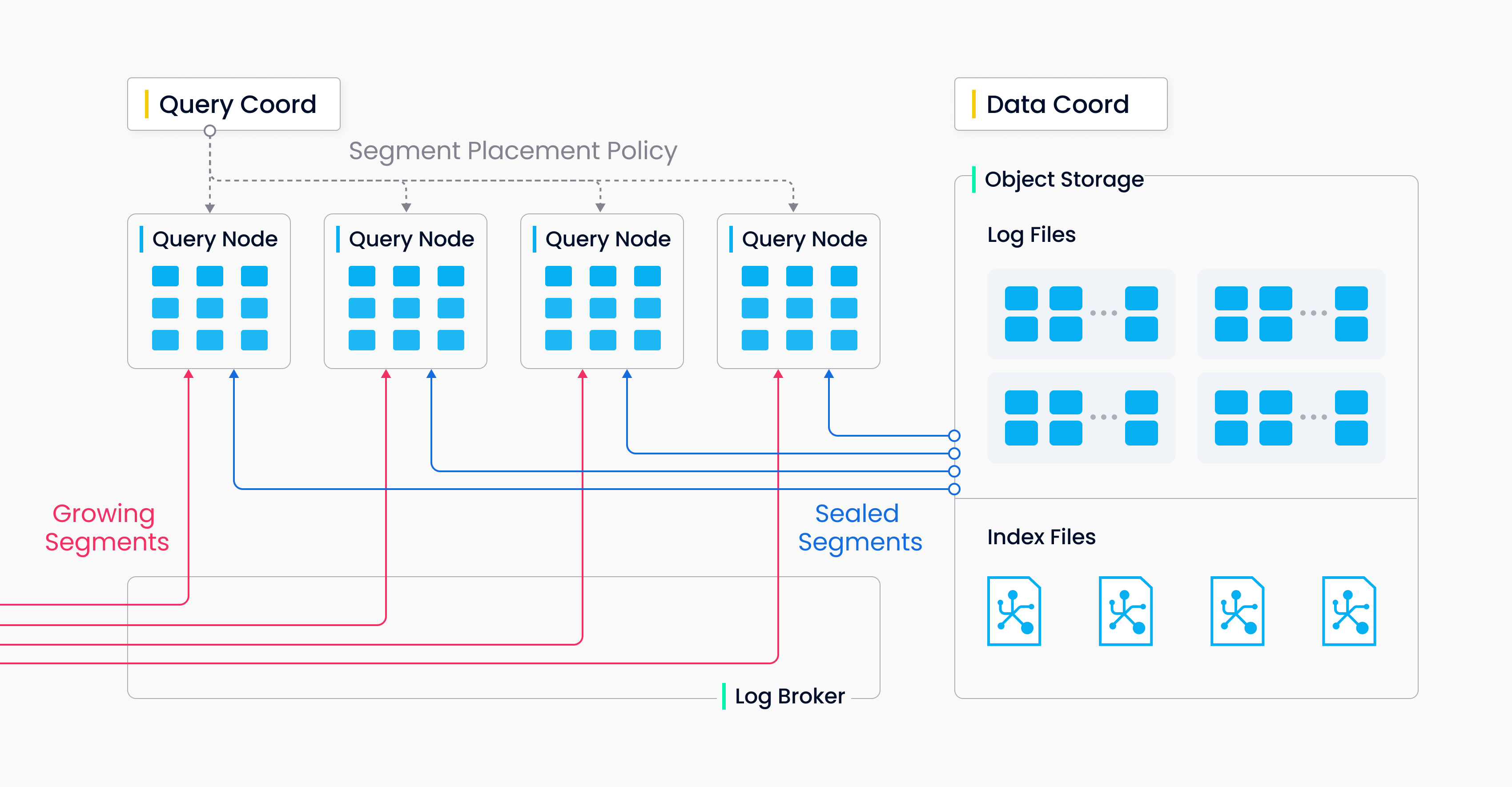
Handoff (Source: Milvus Doc)
There are two types of segments, growing segments (for incremental data), and sealed segments (for historical data). Query node subscribe to vchannel to receive update as growing segments. When growing segment reach to threshold, Data Coord seals it and index building begins. Handoff operation start to turn growing segment to sealed segment, and distribute that will compatible resource (CPU, Memory, Segment Number)
Conclusion

Success
That @all for today, The article about something maybe interesting or not, but if you find something to read and learn more about AI, ML, Data or simple want to learn about Vector Database, I think this one will one of things you can read. But Milvus is look cool and super complicated, to know more you need to handy with Milvus, as least get one for yourself.
Quote
Hope you enjoy the weekend, learn something more with me and doing some great thing. Back to next week, I will consider to write a new session in Kubewekend, but not sure and hope so 😃. Therefore, stay safe, learn something new, have good week and see yeah on next the weekend. Bye