Quote
Hi everyone! It’s been a while since I’ve been in the game, you know, the thing I’ve always loved doing. I recently spent some time researching and setting up a high-availability (HA) database for my own workspace, and I’m ready to share that entire journey with you. This is going to be a long series, therefore getting comfortable and let’s dive into what we’ve got today. I hope you enjoy it!

Why are we should operate HA Database for production-ready ?
If you’ve reached this post, you likely have one of three reasons for wanting to understand high-availability (HA) database operations:
- You’re simply curious about the journey I’m about to share.
- You’re struggling to provision an HA database on your own. When I say ‘on your own,’ I mean from scratch on a raw machine, not in the cloud. This is one of the hardest configurations to get right, and we’ll cover every detail to ensure you know what you’re doing.
- Or, you stumbled upon this post and are simply interested in learning something new. I’ll share specific knowledge on topics like configuration, challenges, key takeaways, and the coolest parts of the process.
Question
Why are you should operate HA for Database ?
It’s toughly question ever, you will encounter lot of troubles if your application downtime and it shouldn’t be occur. Downtime most often occurs during critical processes or connections, and database queries and connections are among the most crucial parts of any system.
If you have time, I encourage you to follow these articles to learn about failover and high availability (HA) in system architecture—a truly important topic that should be a high priority for every developer.
- GeekforGeek - Failover Mechanisms in System Design
- Couchbase - High Availability Architecture: Requirements & Best Practices
High Availability: Is It Really Necessary?
Before you dive into High Availability (HA) for your system, it’s crucial to first clarify what your application is for, read more in this article: Dev.to - Stop Building for “Scale.” You Don’t Have Users Yet
- Proof of Concept (POC) or Minimum Viable Product (MVP): For these projects, HA is completely unnecessary. You’ll only waste time and money on something that doesn’t directly contribute to your core product’s success.
- A Simple System: A major mistake is adding unnecessary complexity. If your database isn’t slow and you’re not experiencing traffic spikes, provisioning an HA database doesn’t make any sense.
- Production-Ready with High Workload: This is the key signal. If your application is in a production environment and consistently handles a high workload, you absolutely need to start considering an HA system and failover at every stage of your program’s lifecycle.
By asking these questions, you can avoid common pitfalls and make the right decision for your system.
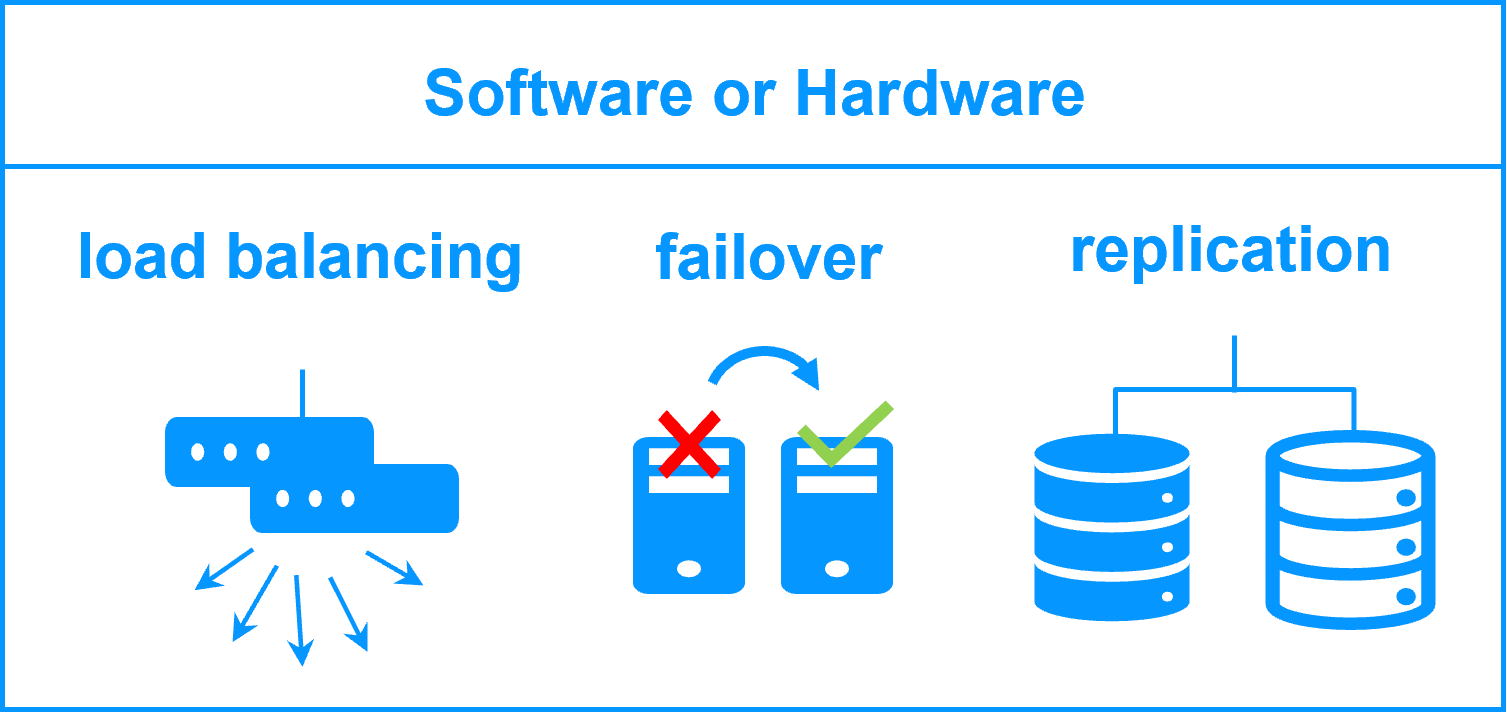
What is High Availability generally mean?
Following the articles Percona - High Availability in PostgreSQL with Patroni, you can imagine the HA Database in specific and HA System Architecture means
Info
”The ability to operate continuously without disruption during an outage. This is achieved by using automatic failover - a technique that seamlessly switches from a failed system to a healthy system with minimal disruption, and all without any human intervention. In short, the system automates the entire recovery process”
Adopting High Availability is a significant step, but your knowledge must evolve as your system becomes more complex. As you integrate new components, you’re also adding more technical debt to your management. There’s no denying the value these systems bring, but that value always comes at a price.
By choosing to set up your own on-premises system, you’ve already proven your courage. So, always stay updated and be direct in your approach. Ensure you have the right tools for debugging, backup, and rollback when you need them.
The options for operating High Availability DB
Before you dive deeper into setting up a High Availability (HA) architecture for these databases, you can review the checklist below. It contains my personal recommendations and suggestions to help you start your journey with HA.
Warning
Please note that this advice is based entirely on my own knowledge and experience, and it may not be right for every situation. Therefore, you must make your own informed decisions about which options to choose and how to leverage these insights to build a successful system.
PostgreSQL
Opensource for High-Availability with PostgreSQL
- Patroni: A template for PostgreSQL High Availability with Etcd, Consul, ZooKeeper, or Kubernetes 🌟 (Recommended)
- Pgpool: A middleware that works between PostgreSQL servers and a PostgreSQL database client
- cloudnative-pg: a comprehensive platform designed to seamlessly manage PostgreSQL databases within Kubernetes environments
- repmgr: a suite of open-source tools to manage replication and failover within a cluster of PostgreSQL servers
- autobase: Enables you to create and manage production-ready, highly available PostgreSQL clusters for Automate deployment, failover, backups, restore, upgrades, scaling, and more with ease.
- PAF: High-Availibility for Postgres, based on Pacemaker and Corosync
Articles for reference
- Linode - A Comparison of High Availability PostgreSQL Solutions
- Youtube - Techno Tim - PostgreSQL Clustering the Hard Way… High Availability, Scalable, Production Ready Postgres 🌟 (Recommended)
- DevOps.vn - Triển khai PostgreSQL high availability với Patroni trên Ubuntu (Cực kỳ chi tiết) 🌟 (Recommended)
- Percona - High Availability in PostgreSQL with Patroni 🌟 (Recommended)
- Palark - Migrating a PostgreSQL database cluster managed by Patroni 🌟 (Recommended)
- Portworx - Kubernetes Operator for PostgreSQL: How to Choose and Set Up One
MongoDB
Info
By them own, MongoDB built-in already support high-availability, in generally, it will not executing but if you dive a bit to architecture, you will learn how can work with MongoDB
Opensource for High-Availability with MongoDB
- MongoDB - ReplicaSet: a group of
mongodprocesses that maintain the same data set. Replica sets provide redundancy and high availability, and are the basis for all production deployments. - Percona Operator for MongoDB: a Kubernetes-native application that uses custom resources to manage the lifecycle of Percona Server for MongoDB clusters
- mongodb-kubernetes: Controllers for Kubernetes translate the human knowledge of creating a MongoDB instance into a scalable, repeatable, and standardized method.
Articles for reference
- Medium - High-availability MongoDB Cluster Configuration Solutions 🌟 (Recommended)
- Medium - Configure 3 nodes replica set of MongoDB on AWS EC2
- MongoDB - Deploy a Self-Managed Replica Set 🌟 (Recommended)
- Medium - Setting Up MongoDB Cluster: Replication, Sharding, and High Availability
- Medium - MongoDB primary failover with Keepalived (with MongoDB cluster)
MySQL
Opensource for High-Availability with MySQL
- vitess: a database clustering system for horizontal scaling of MySQL
- orchestrator: a MySQL high availability and replication management tool, runs as a service and provides command line access, HTTP API and Web interface
- MySQL Group Replication: Enables you to create elastic, highly-available, fault-tolerant replication topologies.
- InnoDB Cluster: An InnoDB Cluster consists of at least three MySQL Server instances, and it provides high-availability and scaling features
- MySQL Operator for Kubernetes: Manages MySQL InnoDB Cluster setups inside a Kubernetes Cluster. MySQL Operator for Kubernetes manages the full lifecycle with setup and maintenance including automating upgrades and backups.
- Tanzu for MySQL on Kubernetes: a Kubernetes Operator that automates provisioning, management, and operations of dedicated MySQL instances running on Kubernetes.
Articles for reference
- StackExchange - Mysql Group replication vs Mysql Cluster
- Mydbops - MySQL Replication Options: Native vs. InnoDB Cluster
- Percona - InnoDB Cluster Setup: Building a 3-Node High Availability Architecture (MySQL)
- Portworx - MySQL on Kubernetes: Step-By-Step Guides to Run MySQL on the Most Popular K8s Platforms
- Youtube - How to Set Up Vitess for High Availability in Production (HAProxy & Keepalived)
- GitHub - MySQL High Availability at GitHub
ElasticSearch
Info
Same as MongoDB, the elasticsearch built-in already support high-availability configuration, you can dive more into documentation to see more of them
Opensource for High-Availability with ElasticSearch
- ElasticSearch ReplicaSet
- Cross-cluster replication (CCR): a feature in Elasticsearch that allows you to replicate data in real time from a leader cluster to one or more follower clusters.
- Elastic Cloud on Kubernetes (ECK): Extends the basic Kubernetes orchestration capabilities to support the setup and management of Elasticsearch
Articles for references
- Viblo - Clustering và Khả năng Khả dụng Cao (High Availability - HA) trong Elasticsearch
- ElasticSearch - Elasticsearch shards and replicas: A practical guide
- Geeksforgeeks - High Availability and Disaster Recovery Strategies for Elasticsearch
Conclusion

Success
That’s all for first session of high-availability database series, I hope you can find a good information and directly touch to your importance part for making decision, should or not to enhance your database
Quote
Turn back and bring a couple thing new for my audiences, that’s pretty inspired me a lot, so hope you always stay tune, be wealthy and healthy, and see what you can get own from high-availability journey by your self
Check about the series of high-availability database of mine below 👇