Data Engineer

Articles
- Medium - Data Pipeline Development with MinIO, Iceberg, Nessie, Polars, StarRocks, Mage, and Docker
- Medium - ETL and ELT 🌟 (Recommended)
- Medium - ELT with Fabric, Azure and Databricks
- Medium - The Change Data Capture (CDC) Design Pattern 🌟 (Recommended)
- Medium - Apache Airflow Overview
- Blog - Data Lake vs Data Warehouse 🌟 (Recommended)
- ML4Devs - Scalable Efficient Big Data Pipeline Architecture
- MonteCarlo - Data Pipeline Architecture Explained: 6 Diagrams and Best Practices 🌟 (Recommended)
- Medium - Data Engineering Best Practices: How Big Tech & FAANG Firms Manage and Optimize Apache Kafka
- Medium - 5 Steps to Build Efficient Data Pipelines with Apache Airflow
- Blog - A Primer on Data Warehouses 🌟 (Recommended)
- Blog - Data Industry Primer 🌟 (Recommended)
- Onehouse - Comprehensive Data Catalog Comparison 🌟 (Recommended)
Awesome Repositories
- awesome-apache-airflow: Curated list of resources about Apache Airflow
- awesome-bigdata: A curated list of awesome big data frameworks, resources and other awesomeness.
- awesome-data-engineering: A curated list of data engineering tools for software developers
- awesome-datascience: 📝 An awesome Data Science repository to learn and apply for real world problems.
- awesome-etl: A curated list of awesome ETL frameworks, libraries, and software.
- awesome-open-source-data-engineering: A curated list of open source tools used in analytics platforms and data engineering ecosystem
- awesome-workflow-engines: A curated list of awesome open source workflow engines
- data-engineer-handbook: a repo with links to everything you’d ever want to learn about data engineering
- data-engineering-roadmap: A comprehensive roadmap tailored for data engineering professionals at all levels
- HelloDATA BE: an enterprise data platform built on top of open-source tools based on the modern data stack
Blogs
- Medium - Vu Trinh: Tech blogger who cover a lot information about databases and data engineers 🌟 (Recommended)
- Medium - Data Engineers Things 🌟 (Recommended)
- Datacamp 🌟 (Recommended)
- LakeFS 🌟 (Recommended)
- Practical Data Engineering 🌟 (Recommended)
- Medium - Kai Waehner: echnology Evangelist — www.kai-waehner.de → Big Data Analytics, Data Streaming, Apache Kafka, Middleware, Microservices
- r/dataengineering
- Medium - Alex Merced: A Tech Blogger for involving the great article with datalake, especially with Iceberg and techstack attachment
Organization
- Big Data Europe: Integrating Big Data, software & communicaties for addressing Europe’s societal challenge
- DataTalksClub: The place to talk about data
Landscape
- LakeFS - The State of Data Engineering 2024 🌟 (Recommended)
- Practicle Data Engineering - Open Source Data Engineering Landscape 2024
- Practicle Data Engineering - Open Source Data Engineering Landscape 2025 🌟 (Recommended)
- Blog - The Ultimate Data Engineering Roadmap (2025) – Built by a Data Engineer
- Portable - 100+ Best ETL Tools List & Software (As Of February 2025)
Topic
- Data
- Data Engineering
- Dataflow
- Data Processing
- Data Science
- Data Warehouse
- Data Lake
- LakeHouse
- ETL
- ELT
Youtube
CDC Pattern
Note
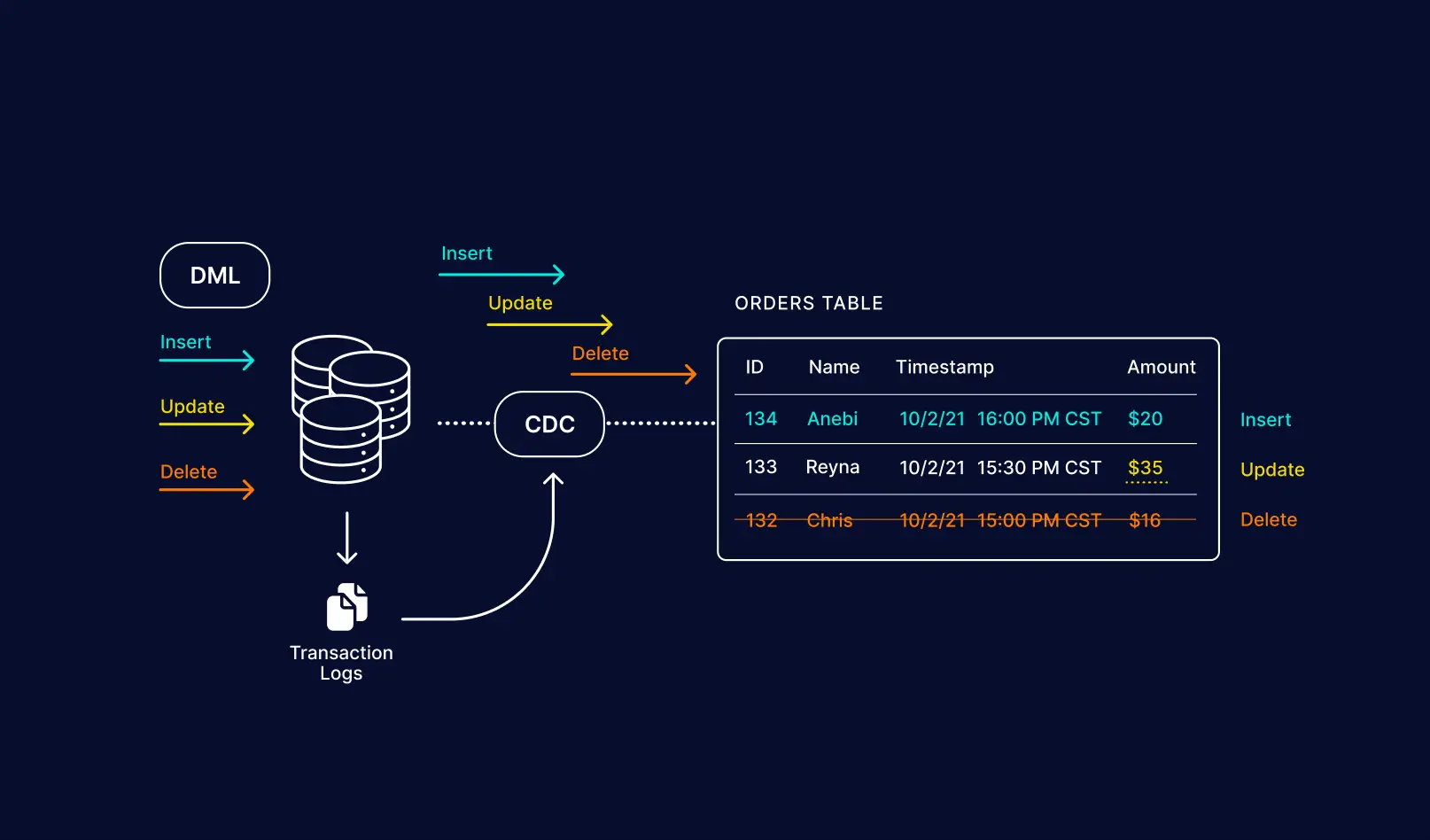
What is CDC?
CDC as a mechanism that constantly monitors the original data system for changes, extracts them, and distributes them to upstream systems. Change Data Capture excludes the process of bulk data loading by implementing incremental loading of data in nearly real-time.
- Blog - Change Data Capture (CDC)
- Medium - The Change Data Capture (CDC) Design Pattern
- Estuary - Types Of Change Data Capture (CDC) For SQL: Choose Wisely
- Estuary - Why You Should Reconsider Debezium: Challenges and Alternatives
- Medium - Is there an Alternative to Debezium + Kafka?
Data Engineer Tools (Curious Version 🔭)
Data Orchestration Workflow
- kestra: ⚡ Workflow Automation Platform
- prefect: A workflow orchestration framework for building resilient data pipelines in Python.
DataLake / Lakehouse
- openhouse: An open source control plane designed for efficient management of tables within open data lakehouse deployments
Streaming Process
- bytewax: Python Stream Processing
Data Engineer Tools

Big Data
- Spark: A multi-language engine for executing data engineering, data science, and machine learning on single-node machines or clusters 🌟 (Recommended)
- spark-docker: Official Dockerfile for Apache Spark
- spark-standalone-cluster-on-docker: Learn Apache Spark in Scala, Python (PySpark) and R (SparkR) by building your own cluster with a JupyterLab interface on Docker. ⚡
- docker-spark-iceberg: Spark + Iceberg Quickstart Image
- Trino: The distributed SQL query engine for big data, formerly known as PrestoSQL 🌟 (Recommended)
CDC
- debezium: Change data capture for a variety of databases 🌟 (Recommended)
- flink-cdc: Flink CDC is a streaming data integration tool
Data Orchestration Workflow
-
airbyte: The leading data integration platform for ETL / ELT data pipelines from APIs, databases & files to data warehouses, data lakes & data lakehouses. Both self-hosted and Cloud-hosted. 🌟 (Recommended)
-
airflow: A platform to programmatically author, schedule, and monitor workflows 🌟 (Recommended)
- Astronomer Registry: Building Blocks for your Apache Airflow Data Pipelines.
- Astro: A fully-managed SaaS application for data orchestration that helps teams write and run data pipelines with Apache Airflow